JVM中提供的synchronized和Lock锁都是JVM级别的,也就是说synchronized和Lock只在同一Java进程内有效,当我们需要实现多个JVM进程之前的线程互斥时,我们就需要使用分布式锁了。
注意:相比单机锁,分布式锁并不能提高性能,甚至由于网络IO,会降低系统的性能。在高并发环境,可以先尝试获取单机锁,如果单机锁获取失败则无需尝试获取分布式锁,避免多余的网络IO降低系统性能。如果获取单机锁成功,再尝试获取分布式锁。
分布式锁特性
- 互斥性:保证只有一个线程持有同一把锁。
- 健壮性:避免死锁,锁不会被永久持有,即使服务奔溃了,也要保证锁在一定期间内会被安全释放。
- 高可用性:除非整个分布式系统瘫痪,只要有服务存活,都允许获取和释放锁。
- 安全性:谁上的锁由谁释放,不能被其他线程解锁。
常见的分布式锁方案
- 基于数据库实现
- 基于Redis实现
- 基于Zookeeper实现
- 基于Etcd实现(etcd:一款比Redis更骚的分布式锁的实现方式!用它)
根据获取分布式锁失败后的操作,可以将上述方案进行简单分类:
- 类CAS自旋式获取分布式锁:MySQL、Redis
- Event事件通知后再尝试获取分布式锁:Zookeeper、Etcd
JVM的锁获取失败,为了避免线程上下文切换,一般会进行CAS自旋,自旋到一定次数依然获取失败后线程才进入休眠状态。但分布式锁由于有网络IO,所以类CAS自旋式获取分布式锁的方式并不能提高性能,还会频繁的网络请求,Event事件一般基于长连接,开销也不小,但相对来说还是基于Event事件的方式更好些。
无论采用哪种方式,我们应该保证一个JVM,同时只有一个线程去尝试获取同一把分布式锁(获取分布式锁前需先获取JVM锁)。
基于数据库实现
利用唯一索引
加锁
1 | insert into methodLock(method_name,desc) values ('method_name','desc'); |
解锁
1 | delete from methodLock where method_name ='method_name'; |
小结
- 数据库存在单点故障,会导致业务系统不可用。
- 锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
- 锁只能是非阻塞的,因为 insert 操作一旦插入失败就会直接报错,没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
- 这把锁是不可重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
基于Redis实现
加锁
1 | SET key value PX NX |
SET key value [EX seconds|PX milliseconds|KEEPTTL] [NX|XX]
EXseconds – Set the specified expire time, in seconds.PXmilliseconds – Set the specified expire time, in milliseconds.NX– Only set the key if it does not already exist.XX– Only set the key if it already exist.KEEPTTL– Retain the time to live associated with the key.
NX可以保证只有一个线程能够获取到同一把锁(也就是只有一个线程能够SET成功)
PN可以保证不会出现死锁(一段时间后,锁会自动过期)
发布订阅+超时后获取
上面分析过,采用类CAS自旋获取分布式锁的方式会导致频繁的网络请求。所以这里可以进行一定的优化。
采用发布订阅的方式,释放锁时,发布锁释放消息,收到消息的JVM进程再尝试获取锁。或者一段时间(可以设置相对较长)没有收到消息,再尝试获取分布式锁(超时时间的作用是防止客户端没有发布消息)。
守护线程续租
当业务执行的时间大于锁超时时间,无法保证只有一个线程获取同一把锁。
所以在获取到锁后,在锁超时之前应该给锁进行续租(重新设置超时时间)。
解锁
解锁时,为了防止锁被错误的释放,可以加上UUID,使用UUID+线程ID的方式来进行标识(UUID只需要生成一次即可)。所以解锁的操作就是 delete if exist and value = 锁标识,但是Redis没有这个原子命令,需要借助Lua脚本,例如:
1 | if (redis.call('get', KEYS[1]) == ARGV[1]) |
高可用 Trade off
因为Redis集群的主从复制是异步的,当发生主备切换时,可能导致多个线程获取到同一把锁。
这个时候就要进行 trade off,如果可以接受极少数情况下多个线程获取到同一把锁,那可以使用集群。否者就需要:
- Redis 使用单点,使用安全级别更高的服务器部署Redis单点服务
- 多个Redis集群,使用 RedLock 算法
RedLock
在 Redis 的分布式环境中,我们假设有 N 个 Redis Master。这些节点完全互相独立,不存在主从复制或者其他集群协调机制。官网文档
现在假设有 5 个完全独立的 Redis Master 节点,他们分别运行在 5 台服务器中,可以基本可以保证他们不会同时宕机。一个客户端加锁/解锁,必须经过以下的五个步骤:
- 获取当前 Unix 时间,以毫秒为单位。
- 依次尝试从 5 个实例,使用相同的 key 和随机值获取锁。(向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间,这样可以避免客户端死等)
- 客户端使用当前时间减去开始获取锁时间(步骤 1 记录的时间)就得到获取锁使用的时间。当且仅当从大多数(这里是 3 个节点)的 Redis 节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
- 如果取到了锁,key 的真正有效时间等于有效时间减去获取锁所使用的时间(步骤 3 计算的结果)
- 如果因为某些原因,获取锁失败(没有在至少 N/2+1 个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的 Redis 实例上进行解锁(即便某些 Redis 实例根本就没有加锁成功)。
为了进一步保证互斥性,假设步骤1的时间为T1,步骤3的时间为T2,锁的有效时间为TTL,那么锁的真正有效时间应该为:
1 | MIN_VALIDITY=TTL-(T2-T1)-CLOCK_DRIFT |
CLOCK_DRIFT:是指时钟漂移的误差值,通常是一个经验值。
更多资料:
基于Zookeeper实现
利用临时节点实现
加锁
创建临时节点,谁创建成功谁获取到锁。
Watch监控
获取失败后,监控该节点的事件,收到事件后,再尝试获取锁。
解锁
断开连接后临时节点会被自动删除。
小结
这种方式实现的是非公平锁,但存在惊群效应,一般不会考虑。
利用临时顺序节点实现
流程图如下:
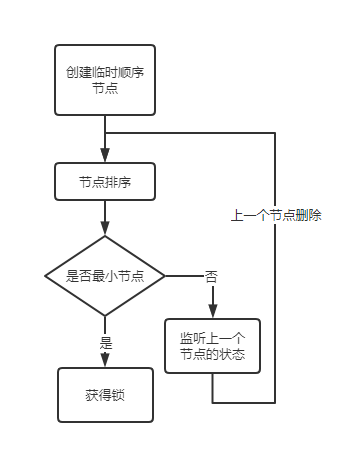
加锁
创建临时顺序节点,排序后如果自己是自小节点则可以获取锁。
否则监控上一个节点,上一个节点删除后,再排序判断自己是否为最小节点直到获取锁成功。
解锁
断开连接后临时节点会被自动删除。
小结
这种方式实现的是公平锁,zk分布式锁一般都是实现的这种方式。
但基于Zookeeper实现的分布式锁也不是完全可靠,例如:客户端A获取到锁之后,由于网络抖动,客户端和ZK集群的session连接断开了,ZK会以为客户端挂了并删除临时节点,这个时候其他客户端就可以获取到分布式锁了。但这种问题并不常见,因为一般Zookeeper的客户端都有重试机制。
小结
上面几种方式,哪种方式都无法做到完美。就像CAP一样,在复杂性、可靠性、性能等方面无法同时满足,所以要根据不同的应用场景选择最适合的方案。
- 从性能角度比较:Redis > Zookeeper > 数据库
- 从可靠性角度比较:数据库 > Zookeeper >= Redis

